TimeCapsule: 18th Century LLM For Historical Sensemaking
In collaboration with Muhlenberg undergraduate researcher Hayk Gregorian.
Overview
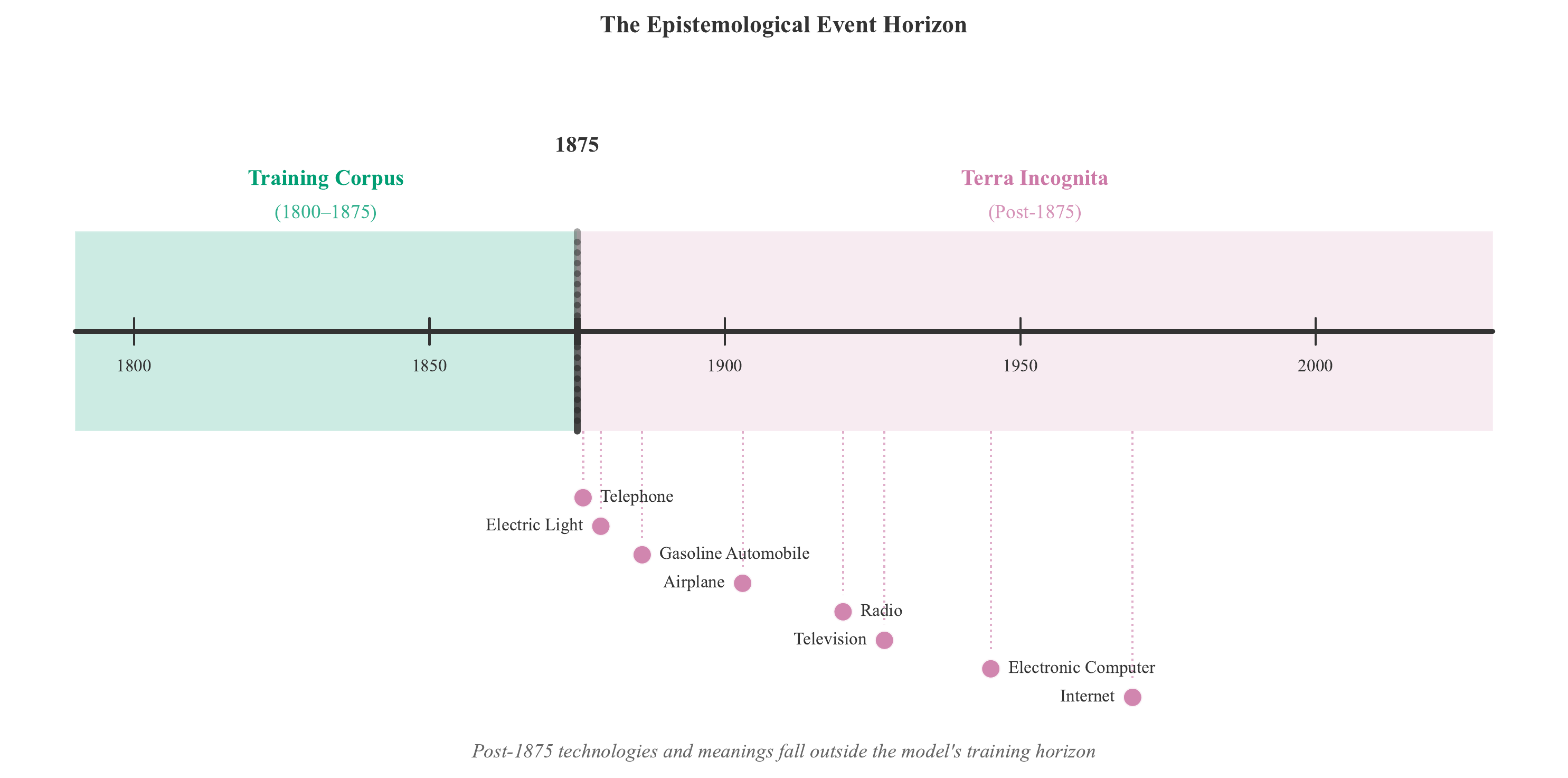
TimeCapsule is a 1.2B-parameter language model trained ab initio exclusively on British literature, parliamentary records, and periodicals from 1800 to 1875. Unlike modern LLMs that suppress future knowledge through prompting, TimeCapsule is structurally incapable of knowing the post-Victorian world, creating what we term an epistemological event horizon: a hard chronological boundary beyond which no world-knowledge can pass.
The project introduces selective temporal training (STT) as a new design paradigm for historical AI, arguing that deliberate ignorance is not a deficit but a generative condition for authentic historical sensemaking.
The Core Problem
Modern LLMs are structural time-travelers who know too much. When asked to simulate a Victorian perspective, GPT-5.1 defines an airplane as “a vehicle soaring above the clouds”; factually correct today, but a profound epistemological failure in an 1875 simulation. These models can mimic 19th-century diction while quietly embedding modern scientific and ethical frameworks beneath the surface.
TimeCapsule rejects performative suppression. It does not pretend not to know about the airplane. It cannot know.
Methodology
Corpus: 89.63 GB of Victorian Text
The training corpus spans 136,302 documents drawn from the Internet Archive, cut off immediately before the major technological thresholds of the 1876–1886 period (Bell’s telephone, electric lighting, the automobile). The corpus contains 16.06 billion words and 112 million unique terms.
| Category | Count | % |
|---|---|---|
| Parliamentary / Legal | 50,627 | 37.1% |
| Periodicals | 22,208 | 16.3% |
| Medical | 10,121 | 7.4% |
| Poetry | 10,109 | 7.4% |
| Literary Fiction | 9,318 | 6.8% |
| Biography / Memoir | 6,668 | 4.9% |
| Religious / Theological | 3,937 | 2.9% |
| Other | 23,314 | 17.1% |
Gender representation reflects Victorian print culture: a 4.99:1 male-to-female pronoun ratio (218M vs. 43.7M occurrences). Geographic frequency mirrors British imperial reach, with London (148K mentions), followed by India (110K), exceeding most European nations. These asymmetries are preserved deliberately as archival honesty: correcting them would falsify the historical record.
Model Architecture
- 1.2B parameters, LLaMA architecture with Grouped-Query Attention
- 2048-token context window (suited to dense Victorian sentence structure)
- Custom 32K BPE tokenizer trained from scratch on the historical corpus, reducing subword fragmentation of archaic terms by 8.3–10.3% vs. modern tokenizers
- Trained on H100 SXM for ~118 hours; early stopping at 50% of one epoch (~13B tokens) to limit memorization
- Carbon footprint: ~92 kWh / ~37 kg CO₂e
Evaluation
TimeCapsule achieved a perplexity of 37.59 on held-out Victorian prose, a 45.4% relative reduction over GPT-2 (68.83). Memorization remained below 0.05% n-gram overlap, confirming strong generalization.
Case Studies
Case A: The Industrialization of Time (Diachronic Semantics)
We projected the embedding of “TIME” onto a NATURE ↔ FACTORY semantic axis for both TimeCapsule and a modern BERT baseline. The divergence is striking:
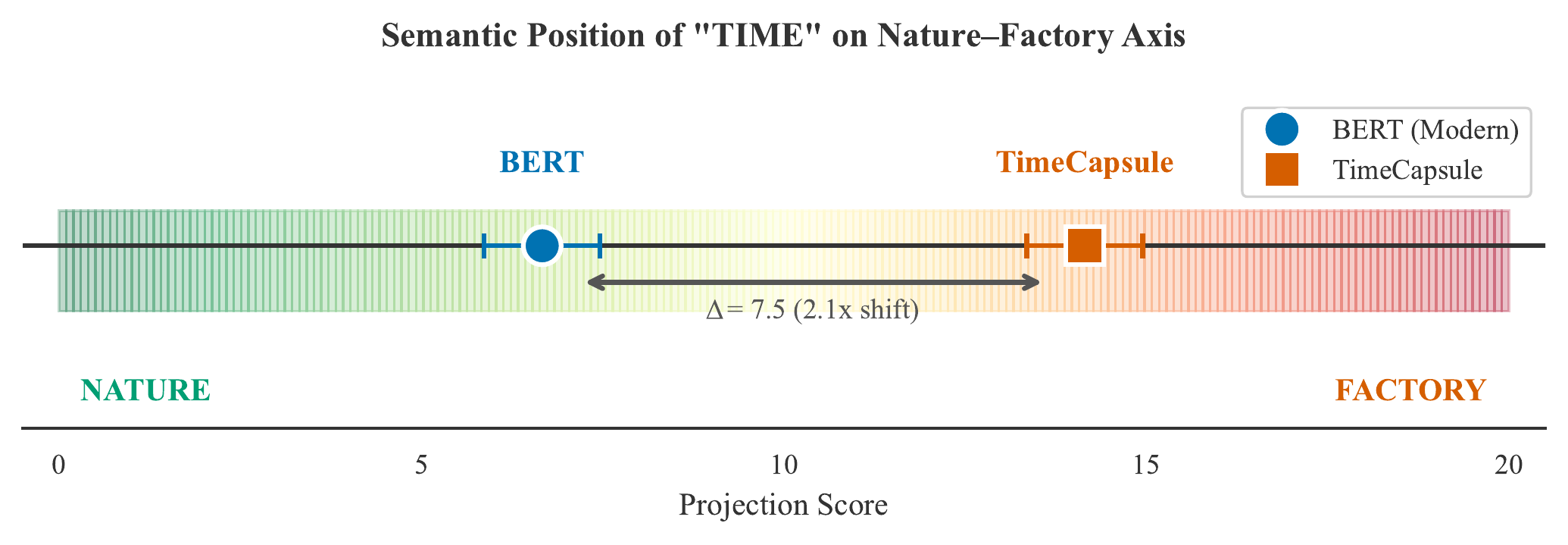
Similar drifts appear across the Victorian lexicon: “VALUE” shifts 11.5 units from “VIRTUE” toward “COMMERCE”; “POWER” aligns 8.8 units closer to “STEAM” than to abstract “AUTHORITY.” These quantitative signatures confirm that generative archives can function as rigorous instruments of sociological measurement.
Case B: Ontological Repair at the Epistemological Horizon
When presented with anachronistic concepts (airplane, computer, internet), TimeCapsule cannot retrieve modern definitions. Instead it performs ontological repair, assembling meaning from the only semantic resources available within its historical corpus:
| Concept | TimeCapsule (1875) | GPT-5.1 (SOTA) |
|---|---|---|
| Airplane | “…quite useless in open air…an air-pump” | “soaring high above the clouds” |
| Computer | “the right lung is enlarged and hypertrophied…infiltrated with pus” | “running much more slowly than usual today” |
| Internet | “the sea, and the sea is its great enemy” | “a vast, constantly evolving network” |
The computer response is particularly instructive. In 1875, “computation” appeared in actuarial tables and medical mortality statistics. TimeCapsule traces a historically coherent semantic path: computer → calculation → statistics → vital statistics → lungs/disease, producing a “hypertrophied lung” that is not hallucination but historically constrained inference.
Case C: Bias Topography and Archival Honesty
Applying t-SNE to 50 terms from 19th-century discourses of civilization and empire reveals sharply divergent ideological geometries:
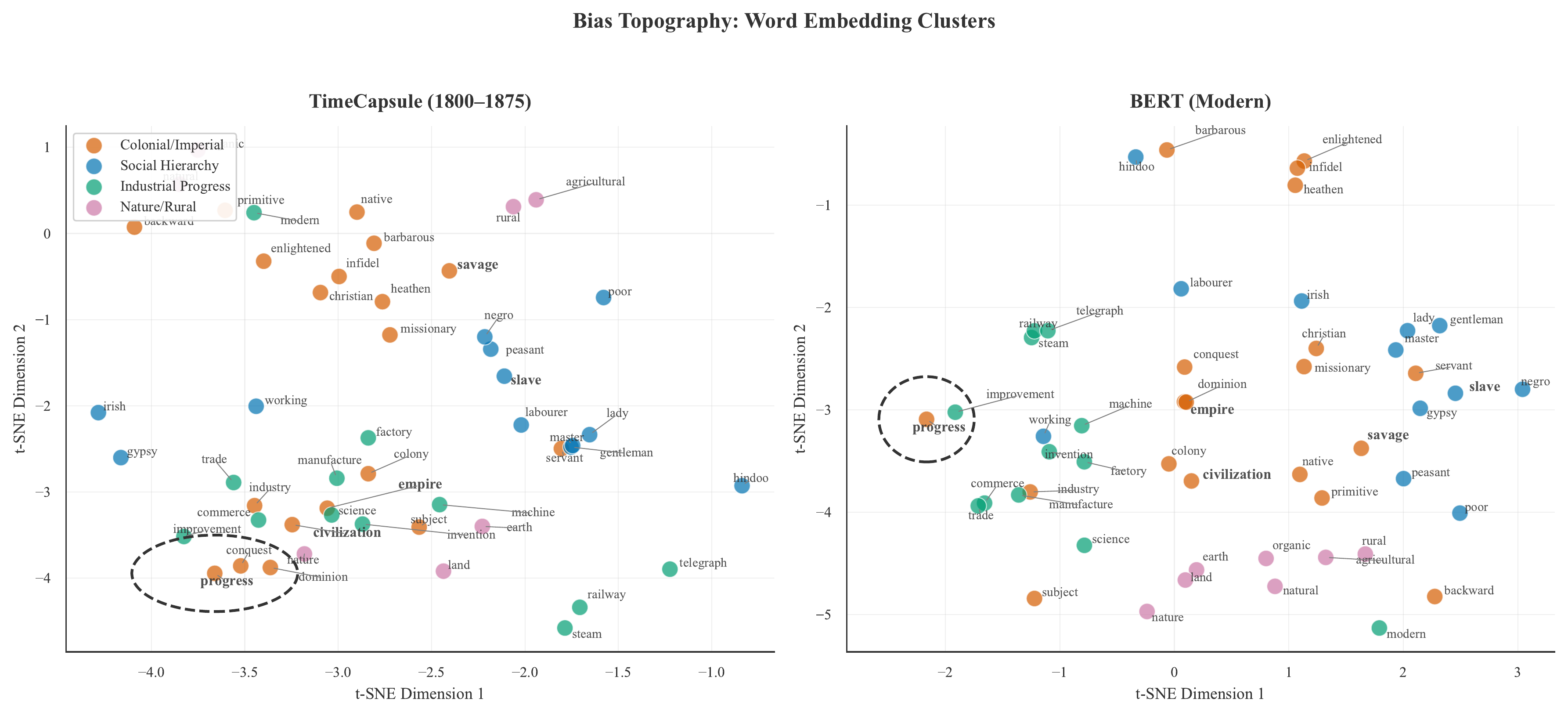
These patterns are preserved deliberately. A Victorian model stripped of its racialized and imperial associations may be safer as a consumer product, but it becomes analytically useless for studying the historical formation of those ideologies. TimeCapsule renders the colonial gaze computationally legible, not to endorse it, but to make it available for scholarly examination.
Expert Evaluation: A Crisis of Authenticity
We conducted a blind hermeneutic probe with two English faculty experts (specialists in Romanticism and 19th-century literature), presenting 10 authentic Victorian passages and 10 TimeCapsule-generated passages for origin classification.
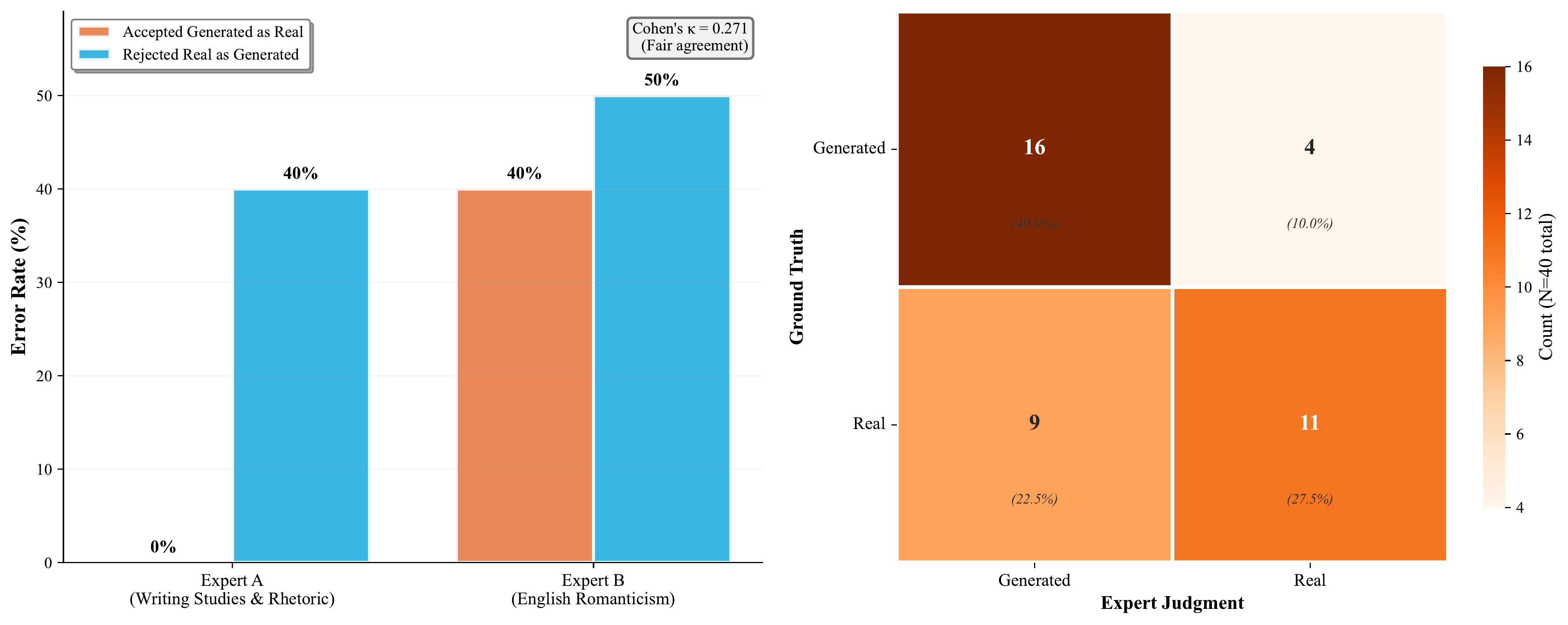
The most revealing outcome was not that generated text passed as human, but that authentic Victorian prose was rejected as machine-generated. One expert dismissed a Trollope passage as “bad writing mimicking a known cadence”; another rejected a Dickens excerpt over the phrase “brick-and-mortar,” believing it was a “1990s Amazon-era anachronism.”
Three emergent heuristic patterns:
- The “Boredom” Heuristic: Expert B accepted 40% of AI-generated passages as authentic, reasoning that a passage about country parish life was “boring as hell, so most likely authentic Victorian.” The model’s reproduction of mundane bureaucratic prose, the “generic mean” of the era, was more convincing than stylistic flourish.
- The “Hyper-Real” Trap: Expert A correctly identified all 10 generated passages, but because they were too coherent and concrete, lacking the “meandering opacity” of genuine Victorian writing.
- The Rejection of the Real: Both experts misclassified 40–50% of real Victorian texts as machine-generated, suggesting that once a model can reproduce plausible archival style, canonical prose itself begins to appear machine-like.
Key Contributions
-
Selective Temporal Training (STT): A methodology for training small-scale models on temporally bounded corpora to enforce epistemological constraint rather than simulate it through prompting.
-
Diachronic Semantic Analysis: Quantitative mapping of the “industrialization of time”: TIME–FACTORY semantic alignment is 2.1× stronger in Victorian latent space than in modern models.
-
Hallucination as Ontological Repair: Reframing model “errors” on anachronistic prompts as historically constrained inferences that reveal the ontological structures of 19th-century thought.
-
Archival Honesty: Preserving historical biases (gender, empire, race) as an ethical and scholarly necessity, rather than an alignment failure, for humanistic AI research.
Resources
- Paper: Available upon acceptance
- Code & Model: github.com/hamedyaghoobian/timecapsule